- November 17, 2025 11:05 am
- by Safvana
- November 17, 2025 11:05 am
- by Ajanth
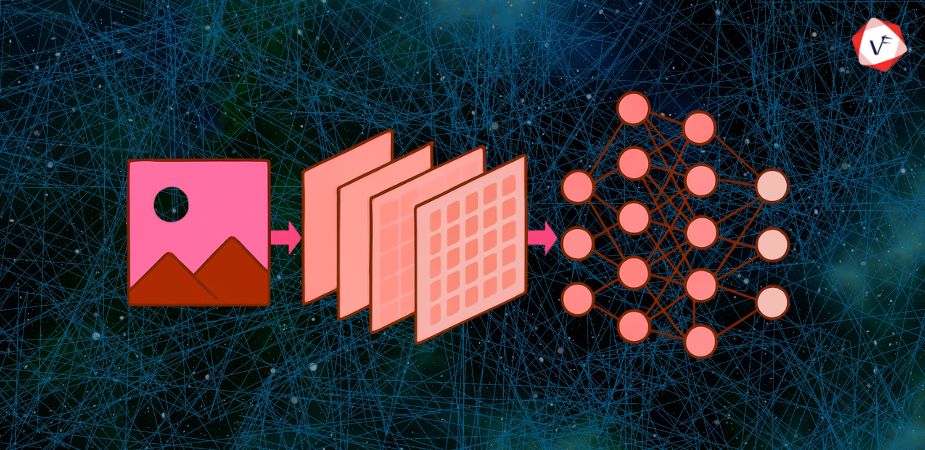
Artificial Intelligence (AI) is a regular part of our daily lives. Whether it's your phone recognizing your face or a self-driving car spotting traffic signs, AI helps machines "see" and make sense of the world. One of the key technologies behind this capability is the Convolutional Neural Network, or CNN.
In this comprehensive guide, we'll explain what a CNN is, how it works, and why it matters—without requiring any technical background.
Before we talk about CNNs, let's start with the basics: Neural Networks. A neural network is a type of computer program inspired by the human brain. Just as your brain uses neurons to think and make decisions, a neural network uses "nodes" that work together to solve tasks.
Now, not all neural networks are the same. Some are better at certain jobs than others. When it comes to images and visual data, CNNs are the best choice for processing and understanding visual information.
CNNs are specially designed to look at images and understand what's inside them. They are exceptionally skilled at picking up patterns, edges, colors, and shapes that define visual elements.
For example, CNNs can answer questions like:
Regular neural networks can attempt these tasks, but CNNs are much faster and significantly more accurate when dealing with visual data.
Let's examine where CNNs are used in the real world and how they impact our daily lives:
Face recognition: Unlock your phone with your face? That's CNNs at work, analyzing facial features and patterns to verify your identity.
Self-driving cars: CNNs help autonomous vehicles detect stop signs, pedestrians, lane markings, and other vehicles, enabling safe navigation.
Medical imaging: Doctors use CNNs to analyze X-rays, MRIs, CT scans, and other medical images, helping identify diseases and abnormalities with high accuracy.
Social media: CNNs can tag your friends in photos automatically by recognizing faces and matching them to profiles.
Security systems: CNNs can spot unusual behavior, detect objects in video footage, and enhance surveillance capabilities.
Basically, if a machine needs to "see" or "look" at something—CNNs are the technology doing the work behind the scenes.
Let's simplify the complex process of how CNNs operate. Think of a photo. To a computer, it's not a picture—it's just a large grid of numbers. Each number represents how bright or what color a tiny dot (called a pixel) is.
A CNN takes this grid of numbers and runs it through several steps to find patterns. These steps include:
This is where CNNs get their name. The convolution layer scans the image using small filters (like little windows), looking for patterns such as straight lines, corners, edges, and textures.
Each filter moves across the image and creates a new map showing where that pattern appears. Think of it like dragging a magnifying glass over a picture and making notes every time you see something important.
After finding patterns, CNNs use a function (usually called ReLU - Rectified Linear Unit) to decide which patterns are useful. It keeps only the important values and removes unnecessary ones—like trimming unnecessary information to focus on what matters.
Now that we've found important patterns, the pooling layer reduces the image size to make it easier to process. It keeps the most important information but uses fewer numbers. This helps speed up processing and prevents overloading the system.
You can think of this like looking at a picture from a distance—you still see the main objects but ignore small, irrelevant details.
After repeating the above steps multiple times, the image becomes a collection of high-level patterns. This final layer connects everything together and makes a decision—like determining "yes, this is a dog" or "no, this is a cat."
This is the part of the CNN that transforms raw image data into a clear prediction or classification label.
Let's say we want to teach a computer to recognize numbers (0 to 9) written by hand. Here's how a CNN would accomplish this task:
The CNN performs this entire process in milliseconds—and can repeat it thousands of times per second with consistent accuracy.
CNNs have three significant advantages that make them exceptionally effective for image processing:
CNNs can recognize objects regardless of their position in the image. Whether a cat appears in the top left, bottom right, or anywhere else in the frame, the CNN will identify it successfully. This property is called translation invariance.
CNNs don't examine every pixel in isolation. Instead, they analyze small patches and reuse filters across the entire image. This approach means they need fewer parameters to remember, which makes them faster and less prone to overfitting or making mistakes.
In early layers, CNNs identify basic features like edges and lines. In deeper layers, they start combining those simple features into more complex structures like eyes, ears, and faces. They build up knowledge progressively, step by step, creating a hierarchical understanding of visual information.
Like people, CNNs need to learn through experience. This happens through a process called training, which is fundamental to developing an effective CNN model.
Here's how the training process works:
Over time, through this iterative process, the CNN becomes increasingly accurate at making correct predictions. This approach is called supervised learning, and it represents one of the most common and effective methods for training CNNs.
While CNNs are powerful tools for computer vision, they're not perfect. Understanding their limitations is important for effective implementation:
CNNs typically require thousands or millions of labeled images to learn effectively. Without sufficient training data, they can become confused or fail to generalize well to new examples. Data collection and labeling can be time-consuming and expensive.
Small, carefully crafted changes in an image—sometimes just a few pixels—can trick a CNN into making completely wrong predictions. For example, adversarial attacks can make a CNN think a panda is a gibbon or misidentify a stop sign as a speed limit sign. This vulnerability poses security concerns in critical applications.
CNNs excel at recognizing shapes and patterns, but they don't truly "understand" what they see in the way humans do. They don't comprehend why a cat appears in an image or the relationship between objects. They simply recognize that certain visual patterns match learned categories.
Teaching a CNN can require hours or even days of processing time on powerful computers. The training process also demands specialized hardware like GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units), which can be costly and energy-intensive.
If you're a developer or a student interested in experimenting with CNNs, several powerful tools and frameworks make implementation more accessible:
These tools enable you to create, train, and test CNNs—even on your laptop for smaller projects. Many offer extensive documentation, tutorials, and community support to help you get started.
CNNs have made remarkable progress since their introduction in the 1990s. The future holds even more exciting developments and applications:
Modern systems increasingly combine CNNs with other neural network architectures like RNNs (Recurrent Neural Networks) for language processing or transformers for attention mechanisms. This integration creates more powerful hybrid systems that can simultaneously "see" and "think," enabling applications like image captioning and visual question answering.
CNNs are being optimized to run on small, resource-constrained devices—such as smartphones, security cameras, drones, and even smartwatches. This edge computing approach means devices don't need to send data to the cloud for processing, improving speed, privacy, and reducing bandwidth requirements.
Automated Machine Learning (AutoML) platforms now enable people without extensive coding experience to build and deploy CNNs using intuitive drag-and-drop interfaces. This democratization of AI technology makes computer vision accessible to a broader audience.
CNNs are revolutionizing healthcare by helping detect diseases from medical images, analyzing climate data for environmental monitoring, examining satellite imagery for agriculture, and even processing images from space exploration missions. Their applications continue to expand across scientific domains.
Convolutional Neural Networks serve as the vision system behind modern artificial intelligence. Even though they may sound complex at first, the core concept is straightforward: break down images into recognizable patterns, identify what matters, and make intelligent predictions based on learned features.
Whether it's recognizing a face, detecting a tumor in medical scans, or helping autonomous vehicles avoid obstacles—CNNs are quietly powering the intelligent tools that shape our future. Their impact spans countless industries and continues to grow as technology advances.
If you're curious about AI, computer vision, or how machines learn to see and interpret the world, CNNs represent an excellent starting point. With the right tools, resources, and mindset, anyone can explore this fascinating field and contribute to the next generation of visual AI applications.
At Vofox Solutions, we leverage cutting-edge CNN technology and deep learning expertise to build innovative AI-powered solutions for businesses worldwide. From computer vision applications to intelligent automation systems, our team transforms complex technical possibilities into practical business value.
Guaranteed Response within One Business Day!

5 Benefits of Choosing an Indian PHP Web Development Company for Global Businesses

Why Hire a Software Development Company in India in 2026?

Hire React Native Developers: Everything You Need to Know Before Starting a Project

Key Services Offered by a React Native App Development Company

React Native Development Services and Their Role in App Development

Guaranteed Response within One Business Day!